自嗨记录之三:FaceMoji
造轮子,爽!
自嗨,爽!
但是话说回来这次其实不是那么的造轮子吧。
起因
之前去参加了朋友婚礼,中间和其他朋友拍了合影。想发到自己的 SNS 上又觉得不合适,于是想找一个感觉很早就见过的工具:把人脸替换成 Emoji。
遗憾的是看了一圈好像没有顺手的,正好最近相对有一些空闲的时间,再加上有 YOLO 在几乎不用考虑人脸检测(指检测哪里有人脸)模型的问题(虽然其实这里是有一些潜在问题的,后面会提),而之前做 Wallpaper Tunnel 超分功能的时候接触过了 Android 端跑 onnx,于是就打算自己上手做一个。
功能
 |
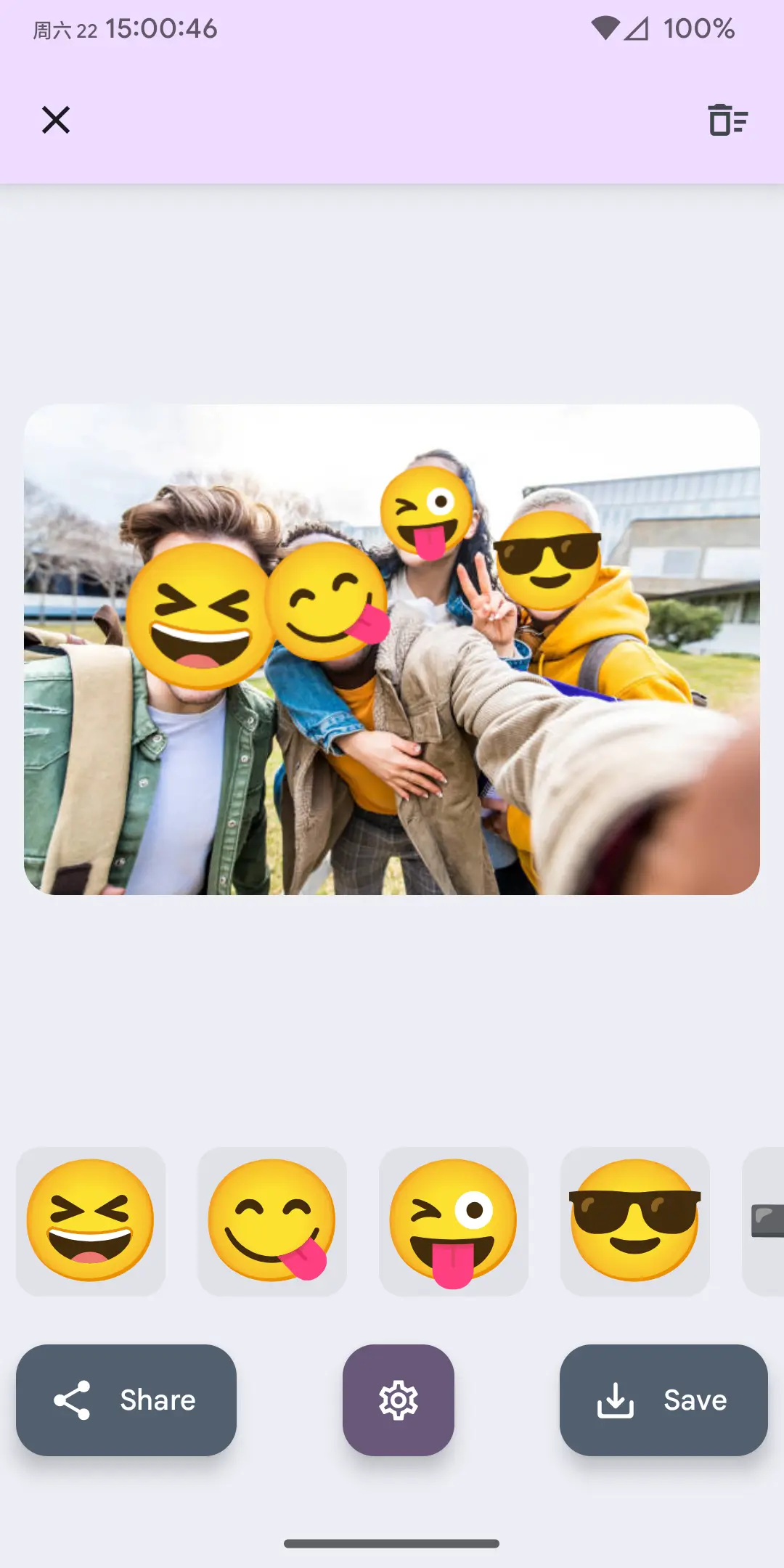 |
- 自动识别图片人脸并以 Emoji 表情覆盖
- 在图片上添加、修改、删除 Emoji
- 隐藏应用图标(此状态下只能从其他应用将图片分享到本应用)
- 导入 Emoji 字体文件
来聊聊
还是惯例来聊聊写代码过程中做出一些选择的原因和遇到的一些问题。
为什么 yolov8-face
YOLO 系列模型可能是目标检测领域最知名的模型,经过了这么长时间的发展在速度和准确性上都有很不错的效果。用来识别图片中的人脸非常合适,但是有一个小的问题,也就是前面提到的:YOLO 模型做的是「目标检测」,它能找到人脸的位置并框起来,但是其预测的边界框是与图片的水平和垂直轴分别平行,因此人脸的朝向就有点麻烦了。而我们在用 Emoji 替换人脸的时候,当然是希望 Emoji 的旋转方向能够至少与头左右转动的方向是一致的。
这就是 yolov5-face 站出来的地方了,这里我没有详细读他们的论文,用 Gemini 总结了一下:
论文的主要工作是重新设计 YOLOv5 对象检测器,使其成为一个高性能的实时人脸检测器,并将其命名为 YOLO5Face。此外,作者还在 YOLO5Face 中添加了一个五点关键点回归头,并使用了 Wing loss 函数来优化关键点的预测。论文的目标是证明不需要为了人脸检测而重新发明新的检测器,通过对现有的优秀通用对象检测器(如 YOLOv5)进行针对性的修改,就可以在人脸检测任务上取得甚至超越专用人脸检测器的性能。作者还设计了一系列不同模型大小的 YOLO5Face 检测器,以适应不同应用场景的需求,包括性能优先和速度优先(如嵌入式或移动设备)。
这里的「五点关键点」是重点,这五个点代表了左眼、右眼、鼻子、左嘴角和右嘴角的位置,有了这五个点,我们就能计算大致上头的转动方向了。(当然仍然是 2D 层面,3D 的实现要更复杂而且对于 Emoji 素材也会有更高的要求)
至于使用 yolov8-face 是因为在 yolov5-face 的 README 中有指向它的链接,既然有新的就用新的了。另外多提一嘴似乎 yolov8-face 转向了使用 YOLO 的 YOLOv8-pose 模型,这里的 “pose” 是姿态识别,他们通过识别身体上的关键点从而对身体姿势有一个估计。前面提到的五个关键点就可以用在这里了。
 |
|---|
| 姿态识别样例 |
顺便其实这个模型不只是能识别「人脸」,虚拟人物的脸有时也可以。
 |
 |
更复杂的 ONNX PrePostProcessor 配置
选好模型下一步就是选择部署到 Android 的方案了,虽然模型开发者其实提供了 ncnn 的版本,但是我更熟悉 onnxruntime 还是用 onnx。
第一步是将 yolov8n-face.pt 转换成 onnx 模型文件,这里我偷了个懒用了别人转的,结果人家场景和我不一样我其实不能直接用,绕了个大弯路。
第二步是给模型增加预处理和后处理步骤,在 Python 里可以很方便的调用 OpenCV 库和 Numpy 库来处理图片和预测结果,但是 Android 平台上就没这么简单了,因此需要把预处理和后处理步骤完整的嵌入到模型中,让模型真正的「端到端」。
这里其实 LLM 就大量的参与了进来,微软提供了给 YOLOv8-pose 添加预处理和后处理的示例,将这个提供给 LLM 作为参考得到了一个可用的转换脚本。
脚本内容
Emoji 实现的选择
我们现在有了可以用的模型,整个流程也就很清楚了:读取图片 -> 模型识别面部位置 -> 在面部位置绘制 Emoji -> 保存或直接分享图片。
在这里面一个关键点就是如何用什么方式绘制 Emoji,Android 上有 Canvas 的 API,可以直接顾名思义来画图的。那么怎么画呢,问了一下 Gemini 说可以以文字形式将 Emoji 绘制在图片上,于是果断选择了这条路。既偷懒掉了找素材/导入素材的过程,又有了一个更换 Emoji 风格的简便方法:导入不同的字体。
于是我变成了开发流程里最拉胯的一环
现在的推理模型太可怕了。
就时间线来说,周日解决了模型的问题,顺便写了应用的初步布局。然后周一晚上+周二晚上几乎全靠模型生成我粘贴就把核心从读图到保存的完整流程跑通了。虽然说之前我自己写应用的时候就高度依赖 LLM,但是这次完全达到了新高度:核心功能部分我所需要做的调整更多是将硬编码文字转成 String 资源以及风格调整,而模型生成代码的速度比我想的速度都快。一直到了后面做一些细节上的功能我才更多自己来写,不过这里也和我一开始对设计没把握好的问题相关。
activity-alias 与隐藏应用图标
FaceMoji 是用来处理图片的,除了打开应用选图片,还应该能接收其他应用分享的图片。还有一个小需求:对于这样一个纯本地的小工具,其实主屏图标不是必要的。但是 <intent-filter> 是静态的,不能用代码动态调整。但是搜了一下有这样一个方法:<activity-alias>。
<activity-alias> 也可以顾名思义,activity 的一个别名,通过这个方式可以区分开 <intent-filter>:原本的 <activity> 负责响应分享的 intent,而别名就负责桌面启动。这样直接通过 Package-Manager 可以直接禁用掉别名从而隐藏桌面图标。
不可免俗的跑马灯
AI 要用跑马灯不是铁律吗。
但是用跑马灯其实是有原因的:
- 从读取进来图片到处理完成需要一定的时间,跑马灯可以用来表示正在处理中。
- 我做了手动添加 Emoji 的功能,毕竟模型不一定能保证绝对准确地识别。而在点击添加按钮之后需要一个指示工具来引导用户点击图片以及同样标示在处理中。
但是跑马灯做起来是有点麻烦的,先直接找 LLM 给的效果基本不可用(当然可能是我的 prompt 问题)。但是搜索看到了一个现成的非动态的 Glowing Effect。
 |
|---|
| Glowing Effect 的效果 |
把这个丢给 LLM 再加上多次的调整之后,终于得到了想要的效果,然后抄了 Gemini 的动画配色。
修改后的 Glowing Card
但是这里还遇到了一个问题:要在图片边缘添加跑马灯特效,需要图片控件和图片的比例完全一致。看了一圈没什么好方法,只能现算图片的比例去设置 Modifier.aspectRatio() 了。
遗憾和变通
-
android:launchMode=singleInstance下Activity的onNewIntent()失效
简单来说本来想实现始终只有一个 Activity 在运行设置了android:launchMode=singleInstance,但这个导致一个问题:打开应用,选一张图片处理完,再从其他应用分享图片过来的话 FaceMoji 就拿不到数据了。最后无奈放弃回到默认状态了。 - 应用体积
启用各种优化之后 apk 体积还是直奔 40MB 了,看了一下模型 12.6MB,onnxruntime的库至少 19.2MB。这就是onnxruntime相比ncnn的劣势了,不过ncnn涉及到 C++ 那些感觉有点麻烦还是先onnxruntime吧。