在 Cloudflare Workers 上部署 Bot
本着能白嫖就白嫖的原则,毛了朋友的代码在 Cloudflare Workers 上放了一个链接转换 Bot 给群友用,正好群友前两天问起来了决定大概写一下怎么部署。
主要的功能就是在 IM 群聊里转换大家发送的 URL:能够显示预览或者去掉跟踪链接之类。
任务
大家或许见过 FxTwitter,把 twitter 的链接里面的域名改成 fxtwitter 就能在 Discord 里显示完成的预览,比如多图、食品、投票等等。
我们这里要部署的 Bot 的功能就是自动完成这样的转换:用户在群聊里发送了特定的链接,这个 Bot 自动发送一个对应的「优化」版本,方面预览或者清除跟踪参数。
Cloudflare Workers
部署的目标平台是 Cloudflare Workers,具体的介绍就交给 Gemini 了:
Cloudflare Workers 是一个无服务器计算(Serverless)平台,它允许开发者将代码(通常是 JavaScript 或 WebAssembly)部署到 Cloudflare 遍布全球的边缘网络上运行。
它的核心工作模式是边缘计算(Edge Computing)。这意味着代码不是在某个固定的、遥远的中央服务器上执行,而是在离最终用户地理位置最近的数据中心内执行。当用户的网络请求(如访问网页、调用API)发生时,Workers 代码会被这个请求事件触发并运行。
这种模式的主要优势在于能实现极低的响应延迟和强大的自动扩缩容能力,同时开发者也无需再关心底层服务器的运维工作。
在定价方面,Cloudflare Workers 的方案非常友好。其免费方案尤其突出,每天为每个账户提供高达 100,000 次的免费请求调用,这对于个人项目、功能原型或中低流量的生产应用来说都绰绰有余。对于更高用量的需求,其付费方案则提供更高的额度并按实际用量计费。
最重要的一点就是其提供了对个人来说用量算是相当充足的免费方案。
原理
这里的原理就更加简单了,绝大多数的情况都只是用正则表达式的匹配和替换,只有处理 Bilibili 的 BV -> AV 号的时候引入了比较复杂的机制(甚至这个机制由于是民间摸索出来的所以看起来非常的「魔法」)。
部署方法
长话短说我们直接看部署方法。
-
注册相应服务账户。
我们在这里需要的是 Github 和 Cloudflare 账户,注册流程都比较简单。对于机器人也需要对应平台的账户。 -
Fork 仓库。(可选)
这里就大言不惭的放上来我自己的 MaaryBot 仓库了。当然这里不 Fork 后面也可以直接使用我的这个仓库来进行部署,但是为了自定义的可能和避免被供应链投毒,仍然还是推荐你自行 Fork 的。
Github 上仓库右上角 Fork 按钮就是按这个的,不再赘述。
当然如果你有自己的需求,也可以自己对代码内容进行修改,这里的代码并不复杂,直接问各家 LLM 应该都能解决你的问题。 -
申请 Bot 账户。
这里也很简单,按照目标平台这里需要找BotFather注册 Bot 账户,一个/newbot然后跟随引导。
完成注册之后会有这样的消息,给出通过 HTTP API 访问 Bot 的 token,需要注意这里的 token 需要妥善存储,避免泄漏。否则谁拿到这个 token 都可以控制你的 Bot 了。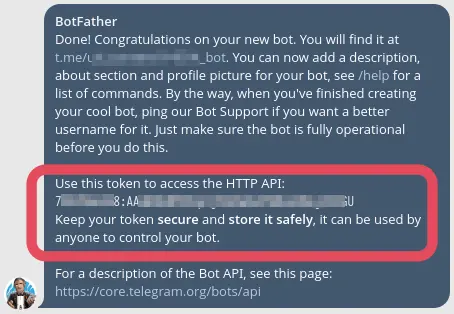
你会看到的 token - 部署仓库。
- 登入 Cloudflare,在左边侧栏找到「计算 (Workers)」并点击。
-
点击「创建」按钮,在 “Workers” Tab 下选择「导入存储库」。
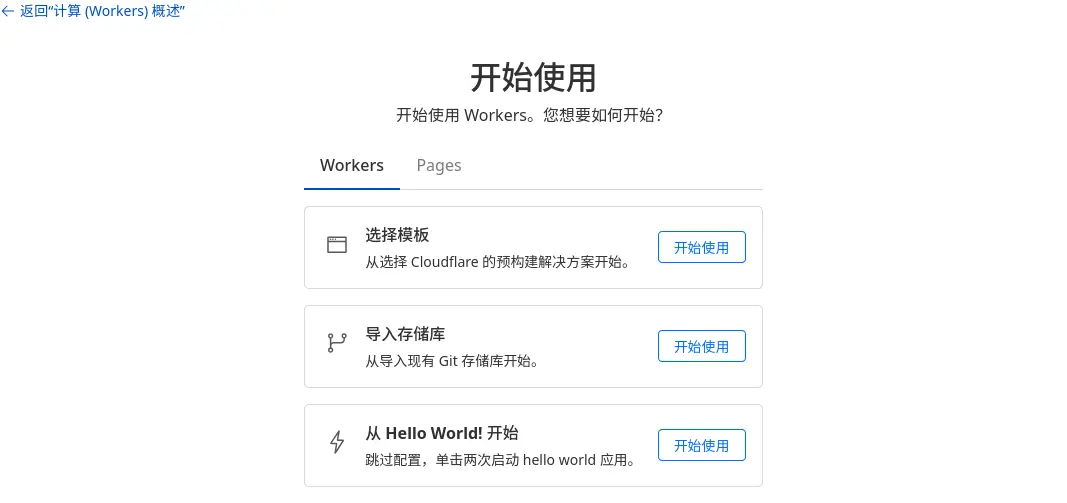
选择导入存储库 -
点击后关联自己的 Github 账户,选择自己的仓库或者「通过 Git URL 克隆公共存储库」。
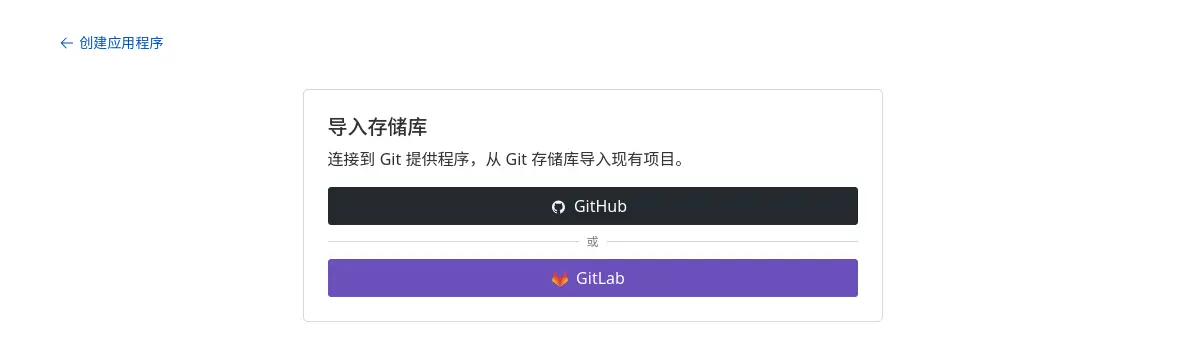
在这里需要关联 GitHub 或 GitLab 账户,根据习惯自由选择 如果你执行了第二步,则在这里选择自己 Fork 的仓库,否则可以直接输入其他仓库地址(比如上面给出来的我的仓库)来进行克隆和部署。
另外这里我没有测试后者,按道理来说 Cloudflare 可能会自动帮你 Fork 一个。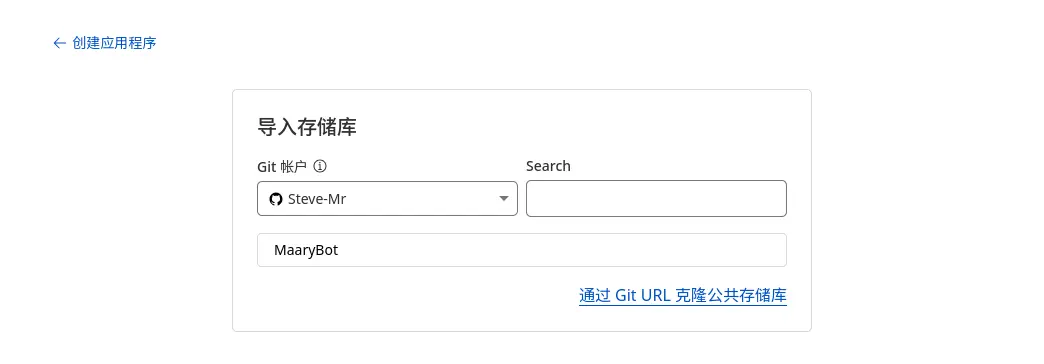
可以通过搜索或者其他方式选择自己的仓库 -
配置和部署。
在这里选择之后理论上不需要进行其他配置了,直接「保存并部署」就好。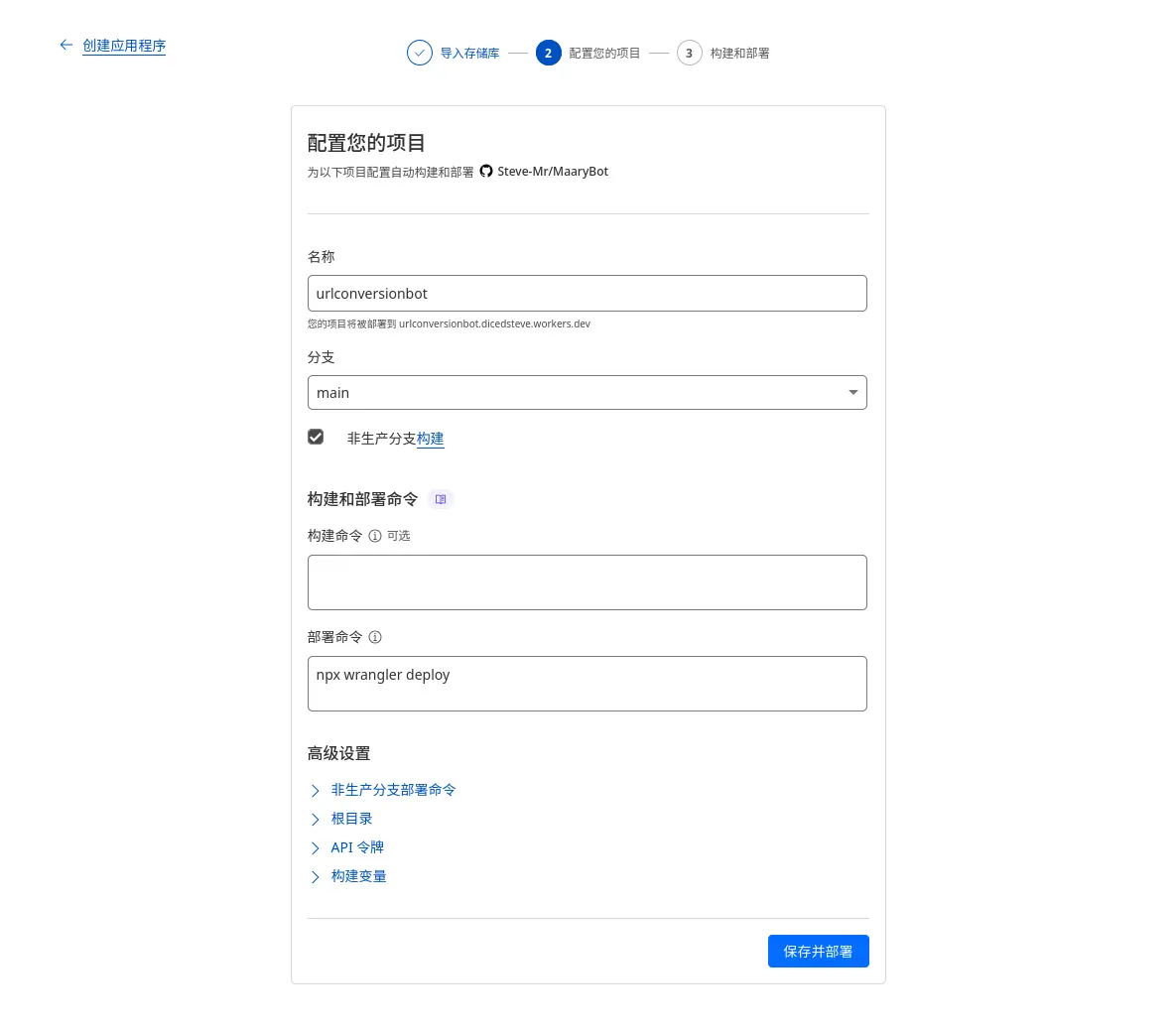
这里应该会自动配置好
-
设置环境变量。
在部署成功之后,还有一个工作,那就是设置环境变量,前面获得的 Bot token 就派上用场了。
在具体项目的设置页,在「变量和机密」下添加两个「密钥」类型的变量:ENV_BOT_TOKEN和ENV_BOT_SECRET。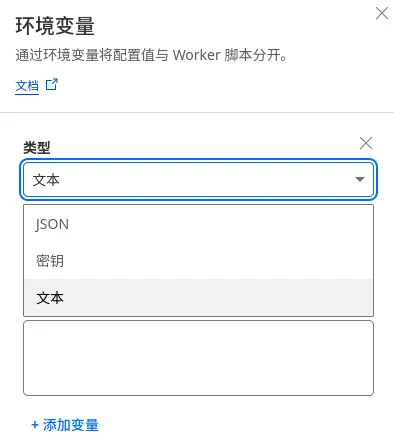
注意在这里选择「密钥」更安全 其中
ENV_BOT_TOKEN就是你前面获取的 token,而ENV_BOT_SECRET可以随意设置,是一串字符就 OK。
这就是设置完的样子 - 连接 Bot。
现在我们在 Cloudflare 端的操作已经完成了,只需要让我们设置的 Worker 能够正常和 Bot 连接并交互就可以了。
项目部署完成后,你会看到一个https://项目名称.用户名.workers.dev格式的链接,在这个链接后面接上/registerWebhook,比如https://my-worker-123.username.workers.dev/registerWebhook。
如果你的部署一切正常,会看到页面上有个Ok,如果是401则可能 token 有误。 - 测试。
现在你给你的 Bot 发送一个链接,它应该能按照预期给你一个处理后的链接了。
一点点坑
朋友大概是参考了这个仓库,这里用的方法是直接往 Cloudflare Workers 里粘代码的方式。
而我看到了 Workers 现在支持直接部署仓库,于是想折腾成一个仓库的方式,搭配环境变量更加优雅一些。本来这个过程并不复杂,我之前在本地也是跟着文档自己搞了个本地项目然后把代码粘进去部署的,但是没想到环境变量翻了车。
显示按照原仓库的方式直接用下面的方式来获取环境变量,也设置了「编译变量」(注意这里后面还要坑我一次),但是编译疯狂报错。
const TOKEN = ENV_BOT_TOKEN // Get it from @BotFather https://core.telegram.org/bots#6-botfather
const WEBHOOK = '/endpoint'
const SECRET = ENV_BOT_SECRET // A-Z, a-z, 0-9, _ and -
然后求助 LLM,给了我这样的结果:
let TOKEN;
let SECRET;
const WEBHOOK = '/endpoint'
addEventListener('fetch', event => {
// 从 env 获取环境变量
TOKEN = event.env.ENV_BOT_TOKEN;
SECRET = event.env.ENV_BOT_SECRET;
看起来非常 OK,但是后来才发现 env 获取环境变量的方式是 Module Workers 用的,而我使用的 Service Workers 其实就是直接 = 获取就好。
关于二者的区别还是直接问 Gemini:
Service Workers (服务工作线程)
- 核心特点:像一个全能的事件监听器。它会监听所有发往你网站的网络请求(比如用户打开网页、点击链接等),然后你可以编写代码来决定如何响应这些请求。
- 工作方式:它只有一个主要的入口文件,所有的代码都从这个文件开始运行。它使用 addEventListener 这种方式来捕捉和处理事件。
- 适用场景:适合处理比较直接、单一的请求和响应逻辑,比如修改一下返回的网页内容、做个简单的跳转等。
Module Workers (模块工作线程)
- 核心特点:像一个现代化的程序。你可以把代码拆分成多个文件(模块),每个文件负责一部分功能,然后在主文件中像搭积木一样把它们组合起来。
- 工作方式:它有一个明确的 fetch 处理函数作为程序的出口。你可以使用 import 和 export 语法来导入和导出不同文件中的代码,结构更清晰。
- 适用场景:适合构建更复杂、功能更多的应用。因为代码被拆分开了,所以更容易管理、复用和协作。这是 Cloudflare 目前推荐和主推的方式。
最终呢结合 LLM 整出来了下面这个方式:
let TOKEN;
let SECRET;
const WEBHOOK = '/endpoint'
addEventListener('fetch', event => {
TOKEN = ENV_BOT_TOKEN;
SECRET = ENV_BOT_SECRET;
终于是顺利通过了编译,但是问题没有结束。
部署之后没法连接 Bot,到这个时候我才发现:原来前面设置的是「编译变量」,而我运行时的环境变量仍然是空的,一个不注意就给自己挖了大坑。后面仔细设置了运行时的环境变量也就正常了。